𝘍𝘳𝘰𝘮 𝘔𝘶𝘮𝘣𝘢𝘪’𝘴 𝘴𝘵𝘢𝘳𝘵𝘶𝘱 𝘦𝘤𝘰𝘴𝘺𝘴𝘵𝘦𝘮 𝘵𝘰 𝘍𝘰𝘳𝘵𝘶𝘯𝘦 500𝘴 𝘢𝘤𝘳𝘰𝘴𝘴 𝘵𝘩𝘳𝘦𝘦 𝘤𝘰𝘯𝘵𝘪𝘯𝘦𝘯𝘵𝘴 – 𝘸𝘩𝘺 𝘦𝘯𝘵𝘦𝘳𝘱𝘳𝘪𝘴𝘦 𝘈𝘐 𝘪𝘴 𝘯𝘰𝘵𝘩𝘪𝘯𝘨 𝘭𝘪𝘬𝘦 𝘵𝘩𝘦 𝘵𝘶𝘵𝘰𝘳𝘪𝘢𝘭𝘴
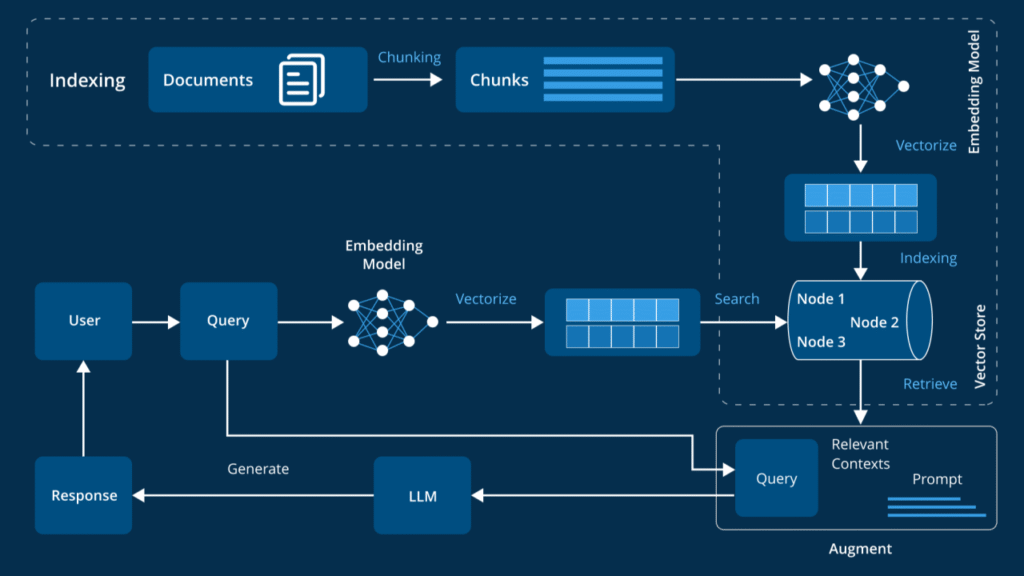
Last Diwali, I was debugging a Retrieval-Augmented Generation (RAG) system at 2 AM, trying to figure out why a pharmaceutical client’s 25-year-old research documents were returning complete nonsense.
The irony wasn’t lost on me – here I was, building “intelligent” systems that couldn’t handle a scanned PDF from 1995.
That moment crystallized something I’d been learning over the past year: 𝗲𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗥𝗔𝗚 𝗶𝘀 𝗯𝗿𝘂𝘁𝗮𝗹𝗹𝘆 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁 𝗳𝗿𝗼𝗺 𝗮𝗻𝘆𝘁𝗵𝗶𝗻𝗴 𝘆𝗼𝘂’𝗹𝗹 𝗿𝗲𝗮𝗱 𝗶𝗻 𝘁𝘂𝘁𝗼𝗿𝗶𝗮𝗹𝘀.
After working with 10+ projects across regulated industries – pharma companies in Pune, investment banks in Singapore, law firms in London – I’ve learned something crucial.
The real challenges have nothing to do with choosing between OpenAI and Claude. They’re about the messy reality of decades-old document repositories and the humans who need to use them.
𝟭. 𝗧𝗵𝗲 𝗗𝗼𝗰𝘂𝗺𝗲𝗻𝘁 𝗤𝘂𝗮𝗹𝗶𝘁𝘆 𝗪𝗮𝗸𝗲-𝗨𝗽 𝗖𝗮𝗹𝗹
Here’s what no one tells you: 𝗲𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗱𝗼𝗰𝘂𝗺𝗲𝗻𝘁𝘀 𝗮𝗿𝗲 𝗮𝗯𝘀𝗼𝗹𝘂𝘁𝗲 𝗴𝗮𝗿𝗯𝗮𝗴𝗲.
I remember sitting with the head of R&D at a Mumbai-based pharma company, watching him scroll through SharePoint folders that looked like digital archaeology. Research papers from the 90s (scanned typewritten pages), mixed with modern clinical trial reports, mixed with handwritten notes someone photographed with their phone.
“Can your AI make sense of this?” he asked, pointing to a folder labeled “Important_Docs_FINAL_v2_USE_THIS_ONE.”
𝘚𝘱𝘰𝘪𝘭𝘦𝘳: 𝘐𝘵 𝘤𝘰𝘶𝘭𝘥𝘯’𝘵.
That’s when I realized the first rule of enterprise RAG: 𝗱𝗼𝗰𝘂𝗺𝗲𝗻𝘁 𝗾𝘂𝗮𝗹𝗶𝘁𝘆 𝗱𝗲𝘁𝗲𝗰𝘁𝗶𝗼𝗻 𝗺𝘂𝘀𝘁 𝗰𝗼𝗺𝗲 𝗯𝗲𝗳𝗼𝗿𝗲 𝗲𝘃𝗲𝗿𝘆𝘁𝗵𝗶𝗻𝗴 𝗲𝗹𝘀𝗲.
𝗖𝗹𝗲𝗮𝗻 𝗣𝗗𝗙𝘀 (perfect text extraction): Full hierarchical processing 𝗗𝗲𝗰𝗲𝗻𝘁 𝗱𝗼𝗰𝘀 (some OCR artifacts): Basic chunking with cleanup 𝗚𝗮𝗿𝗯𝗮𝗴𝗲 𝗱𝗼𝗰𝘀 (scanned handwritten notes): Fixed chunks + manual review flags
This single change fixed more retrieval issues than any embedding model upgrade ever did.
𝟮. 𝗪𝗵𝘆 𝗛𝗥 𝗧𝗲𝗮𝗺𝘀 𝗧𝗮𝘂𝗴𝗵𝘁 𝗠𝗲 𝗔𝗯𝗼𝘂𝘁 𝗖𝗵𝘂𝗻𝗸𝗶𝗻𝗴 𝗦𝘁𝗿𝗮𝘁𝗲𝗴𝘆
The breakthrough on chunking came from an unexpected place: working with HR teams.
Every RAG tutorial says: “Chunk everything into 512 tokens with overlap!” But sit with an HR director trying to find specific policy information, and you’ll quickly see why this is wrong.
When someone asks “What’s our maternity leave policy for contract employees in India?” they don’t want chunks that cut off mid-sentence or combine unrelated policies. They need the complete policy section, with context about exceptions and regional variations.
𝗗𝗼𝗰𝘂𝗺𝗲𝗻𝘁 𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝗺𝗮𝘁𝘁𝗲𝗿𝘀. 𝗔 𝗹𝗼𝘁.
My hierarchical chunking approach: Document level: Title, authors, date, policy type Section level: Policy overview, eligibility, procedures Paragraph level: Specific rules and exceptions Sentence level: For precision queries
The key insight? 𝗤𝘂𝗲𝗿𝘆 𝗰𝗼𝗺𝗽𝗹𝗲𝘅𝗶𝘁𝘆 𝘀𝗵𝗼𝘂𝗹𝗱 𝗱𝗲𝘁𝗲𝗿𝗺𝗶𝗻𝗲 𝗿𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝗹𝗲𝘃𝗲𝗹.
𝟯. 𝗧𝗵𝗲 𝗠𝗲𝘁𝗮𝗱𝗮𝘁𝗮 𝗥𝗲𝘃𝗼𝗹𝘂𝘁𝗶𝗼𝗻 (𝗧𝗵𝗮𝗻𝗸𝘀 𝘁𝗼 𝗗𝗼𝗺𝗮𝗶𝗻 𝗘𝘅𝗽𝗲𝗿𝘁𝘀)
Here’s where I spent 40% of my development time – and it had the highest ROI of anything I built.
Enterprise queries are insanely contextual. A pharmaceutical researcher in Bangalore asking about “pediatric studies” needs completely different documents than a regulatory affairs manager in Frankfurt asking the same question.
𝗧𝗵𝗲 𝘀𝗼𝗹𝘂𝘁𝗶𝗼𝗻? 𝗗𝗼𝗺𝗮𝗶𝗻-𝘀𝗽𝗲𝗰𝗶𝗳𝗶𝗰 𝗺𝗲𝘁𝗮𝗱𝗮𝘁𝗮 𝘀𝗰𝗵𝗲𝗺𝗮𝘀 𝗯𝘂𝗶𝗹𝘁 𝘄𝗶𝘁𝗵 𝗮𝗰𝘁𝘂𝗮𝗹 𝘀𝘂𝗯𝗷𝗲𝗰𝘁 𝗺𝗮𝘁𝘁𝗲𝗿 𝗲𝘅𝗽𝗲𝗿𝘁𝘀.
For pharma clients:
- Document type (research paper, regulatory filing, clinical trial)
- Drug classifications and therapeutic areas
- Patient demographics (pediatric, adult, geriatric)
- Regulatory bodies (FDA, EMA, CDSCO)
For financial services:
- Time periods (Q1 FY24, annual reports)
- Financial metrics and KPIs
- Business segments and geographies
- Regulatory frameworks (RBI guidelines, Basel III)
𝗣𝗿𝗼 𝘁𝗶𝗽: Skip LLMs for metadata extraction. They’re inconsistent. Simple keyword matching works infinitely better.
𝟰. 𝗪𝗵𝗲𝗻 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗦𝗲𝗮𝗿𝗰𝗵 𝗙𝗮𝗶𝗹𝘀 (𝗠𝗼𝗿𝗲 𝗢𝗳𝘁𝗲𝗻 𝗧𝗵𝗮𝗻 𝗬𝗼𝘂 𝗧𝗵𝗶𝗻𝗸)
Pure semantic search fails 𝟭𝟱-𝟮𝟬% 𝗼𝗳 𝘁𝗵𝗲 𝘁𝗶𝗺𝗲 in specialized domains. Not the 5% everyone assumes.
𝗠𝗮𝗶𝗻 𝗳𝗮𝗶𝗹𝘂𝗿𝗲 𝗺𝗼𝗱𝗲𝘀 𝘁𝗵𝗮𝘁 𝗸𝗲𝗽𝘁 𝗺𝗲 𝘂𝗽 𝗮𝘁 𝗻𝗶𝗴𝗵𝘁:
Acronym confusion: “CAR” means “Chimeric Antigen Receptor” in oncology but “Computer Aided Radiology” in medical imaging
Precise technical queries: “What was the exact dosage in Table 3?” Semantic search finds similar content but misses the specific reference
Cross-reference chains: Documents reference other documents constantly. Semantic search misses these relationship networks
𝗧𝗵𝗲 𝗳𝗶𝘅? Hybrid approaches with domain-aware fallbacks: Graph layer to track document relationships Context-aware acronym expansion Rule-based retrieval for precise data points
𝟱. 𝗧𝗵𝗲 𝗢𝗽𝗲𝗻 𝗦𝗼𝘂𝗿𝗰𝗲 𝗥𝗲𝗮𝗹𝗶𝘁𝘆 𝗖𝗵𝗲𝗰𝗸
Most people assume GPT-4 is always better. But enterprise clients have constraints that matter more than benchmark scores:
Cost: API costs explode with 50K+ documents Data sovereignty: Can’t send sensitive data to external APIs Domain terminology: General models hallucinate on specialized terms
I ended up using 𝗤𝘄𝗲𝗻 𝗤𝗪𝗤-𝟯𝟮𝗕 after domain-specific fine-tuning:
- 85% cheaper than GPT-4 for high-volume processing
- Everything stays on client infrastructure
- Fine-tuned on medical/financial terminology
- Consistent response times without API rate limits
𝟲. 𝗧𝗮𝗯𝗹𝗲𝘀: 𝗧𝗵𝗲 𝗛𝗶𝗱𝗱𝗲𝗻 𝗚𝗼𝗹𝗱𝗺𝗶𝗻𝗲 𝗘𝘃𝗲𝗿𝘆𝗼𝗻𝗲 𝗜𝗴𝗻𝗼𝗿𝗲𝘀
Enterprise documents are packed with critical tabular data – financial models, clinical trial results, compliance matrices, salary bands, performance metrics.
Standard RAG either ignores tables or extracts them as unstructured text, losing all relationships. 𝗕𝘂𝘁 𝘁𝗮𝗯𝗹𝗲𝘀 𝗼𝗳𝘁𝗲𝗻 𝗰𝗼𝗻𝘁𝗮𝗶𝗻 𝘁𝗵𝗲 𝗺𝗼𝘀𝘁 𝘃𝗮𝗹𝘂𝗮𝗯𝗹𝗲 𝗶𝗻𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝗼𝗻.
My approach: Treat tables as separate entities with dedicated processing Use pattern recognition for table detection Dual embedding strategy: structured data AND semantic descriptions Preserve hierarchical relationships in metadata
𝟳. 𝗞𝗲𝘆 𝗟𝗲𝘀𝘀𝗼𝗻𝘀 𝗧𝗵𝗮𝘁 𝗔𝗰𝘁𝘂𝗮𝗹𝗹𝘆 𝗠𝗮𝘁𝘁𝗲𝗿
1. Document quality detection first 2. Metadata > embeddings 3. Hybrid retrieval is mandatory 4. Tables are critical 5. Infrastructure determines success
𝗧𝗵𝗲 𝗥𝗲𝗮𝗹 𝗧𝗮𝗹𝗸
Enterprise RAG is 𝟴𝟬% 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴, 𝟮𝟬% 𝗠𝗟.
Most failures aren’t from bad models – they’re from underestimating document processing complexity, metadata requirements, and production infrastructure needs.
But here’s the thing: 𝘁𝗵𝗲 𝗱𝗲𝗺𝗮𝗻𝗱 𝗶𝘀 𝗮𝗯𝘀𝗼𝗹𝘂𝘁𝗲𝗹𝘆 𝗶𝗻𝘀𝗮𝗻𝗲 𝗿𝗶𝗴𝗵𝘁 𝗻𝗼𝘄.
From textile manufacturers in Tamil Nadu digitizing compliance documents, to consulting firms in Gurgaon making their knowledge base searchable – everyone needs these systems.
The ROI, when done right, is transformational. Research teams cut document search from hours to minutes. Compliance teams that spent weeks on audit prep now do it in days.
#AgenticAI #MachineLearning #Enterprise #RAG #DataScience #TechLeadership #ArtificialIntelligence #DigitalTransformation
Leave a Reply