AI’s biggest wins in 2026 won’t come from new models.
They’ll come from the discipline of evaluating, testing, measuring, and proving what actually works for the user.
Behind the scenes, something is shifting: contracts, budgets, even compliance are all starting to demand evidence, not demos.
We’ve lived through three fast years:
- 2023: The LLM rush (everyone worshipped the models).
- 2024: The POC flood (everyone “tried” AI).
- 2025: The Agent year (everyone’s wiring tools and workflows).
2026 will be the year evals go from “nice to have” to contractual – the thing buyers and regulators ask for before you deploy, and the thing finance teams ask for before they fund.
But let’s get precise about what I mean by “evals,” because this word is overloaded.

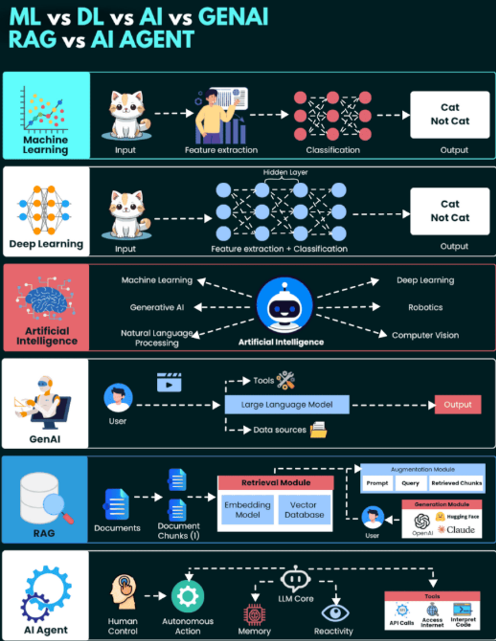
Product evals ≠ model evals (and ≠ observability)
In this blog, when I mention “Evals”, I am mainly pointing towards product evals and obervability in a blanket term. Let’s understand the difference first.
- Model (LLM) evals measure capability in controlled tasks (reasoning, safety, accuracy). These are useful for model selection, not sufficient for business sign-off.
- Product evals measure outcomes in a live product: customer impact, risk, cost, reliability. Think: A/B results, guardrail pass-rates, time-to-resolution, cost-to-serve, incident rates, and audit-ready traces.
- Observability watches operations in real time (latency, errors, spend, drift alerts). It’s how you keep the system healthy after you ship.
One-line rule of thumb: Evals decide “ship/keep.” Observability answers “what’s happening right now?” They work together, but they aren’t the same.
Enterprises buy product outcomes, not leaderboard wins. If your “evals” don’t connect to customer experience, risk, compliance, and ROI, you’re not building for the right outcome.
This is why 2026 tilts toward product evals. We’ll still run LLM evals, but they’ll be one input to a bigger, product-centric evidence loop.
A short timeline through the Eval lens
2023 – Leaderboards and lab metrics. We had a an explosion of models and academic benchmarks. Helpful for science, less helpful for CFOs. What did change: the conversation about transparent, reproducible evaluation started getting louder in the public sphere. Stanford’s HELM work on broader, reproducible benchmarking is a good marker of that shift.
2024 – Institutions formalize “measure before you trust.” NIST released a Generative AI Profile alongside its AI Risk Management Framework – explicitly pushing organizations to govern, measure, and manage risks with evaluation and monitoring built in. Translation: “trust” now requires evidence, not vibes.
The UK’s AI Safety Institute launched Inspect, an open platform to publish and run evaluations – primarily model-level, but the bigger signal is public bodies treating evaluation as infrastructure, not a one-off.
2025 – Evals slip into product workflows. While labs keep refining model tests, product companies keep doing what they’ve always done – experiment, measure, ship – just with AI in the loop now. Netflix, Uber, DoorDash, Booking.com, and LinkedIn have written openly for years about rigorous experimentation at product scale; that playbook is exactly what the AI era needs: tie changes to outcomes, at velocity, with guardrails.
2026 – Regulation + Procurement + Finance. The EU AI Act becomes fully applicable on August 2, 2026 (with gradations by risk). That puts conformity assessment, ongoing monitoring, and documentation in scope for many systems. Buyers in regulated sectors will ask for eval-derived evidence by default. This is the year product evals become the control plane for AI deployments.
Why Evals become non-negotiable in 2026
- Regulators are asking for proof, not promises. NIST is telling organizations to measure and manage AI risks with concrete tests and monitoring. The EU AI Act puts time-bound obligations on evaluation and documentation. If you can’t show your tests, thresholds, and traces, you don’t have a compliance story.
- Procurement teams want predictable outcomes. They’ll ask: “What’s your policy pass-rate? What happens when it fails? How fast can you detect drift? Show me the audit trail.” That’s product eval territory: live metrics, gates, fallbacks, and exportable proof bundles.
- Finance wants the delta. Cost-to-serve, time-to-resolution, defect rate, and risk-adjusted loss. If evals can’t roll up into those numbers, budgets stall. .
- Change never sleeps. Agents, prompts, and tools mutate weekly. Without eval gates and continuous checks, you ship regressions in the dark. Product evals are your headlights.
The market is signaling the same
Industry report states enterprises are losing an estimated $1.9 billion annually due to undetected LLM failures. This suggests the market problem is real and large, but also that current solutions haven’t fully solved it yet.
AI evaluation startups are experiencing rapid growth, with companies like Arize AI raising $70 million, Galileo raising $45 million, Braintrust securing $36 million, and newer entrants like Scorecard AI ($3.75 million) and Trismik (£2.2 million) attracting significant funding in 2025.
These products serve major enterprises including Notion, Stripe, BCG, Microsoft, AstraZeneca, and Thomson Reuters, demonstrating strong enterprise adoption across finance, healthcare, and technology sectors.
Model providers are also moving from quiz-style benchmarks to economically grounded evaluations. OpenAI’s recent announcement around evaluating models on “economically valuable, real-world tasks” is a signal of where the industry is heading: evaluations that look like work, scored in ways executives can understand. I’m not using it as a yardstick in this piece, just noting the shift in mindset: evals as evidence for real work, not just leaderboard points.
Public bodies are pushing too: the UK’s AI Safety Institute open-sourced evaluation tooling (Inspect) to make it easier for the whole ecosystem to measure consistently. Again, the signal is the same: evaluation is infrastructure.
The enterprise playbook for 2026
Step 1 – Define success in business terms. Pick the top one or two workflows. Baseline: cost-to-serve, time-to-resolution, defect rate, incident likelihood. This is important, if you skip this, you can’t show ROI later.
Step 2 – Turn policies into tests. Privacy, safety, factuality, refusal correctness, brand tone. Automate checks where you can; keep human review for what genuinely needs judgment. Look at NIST’s guidance to move beyond documentation, and measure and manage. I love Hamel’s guidance on Evals, they are practical and makes sense.
Step 3 – Build the gate. Ensure no change ships without passing scenario tests that mirror the real workflow. Treat every model/prompt/tool update as a release candidate.
Step 4 – Deploy with canaries and a kill switch. Expose to a small slice. Compare against baseline. Auto-rollback if guardrails trip or metrics regress. I would take inspiration from Netflix’s Sequential Testing principles.
Step 5 – Log everything. Prompts, versions, model/tool hashes, data lineage, evaluator settings, results, sign-offs. You’re building your audit pack as you operate, so log everything.
Step 6 – Report like an owner. Every month, share a simple one-pager: how policies performed, what it cost vs. expected, where risks went down, and what you changed as a result. That’s how you build trust and keep the budget flowing.
What changes in 2026
- What’s changing: Evals are moving from “nice to have” to contractual. RFPs don’t just ask “does it work?” – they now demand policy pass-rates, fallback design, drift detection speed, and evidence. CFOs aren’t satisfied with burn rates – they want cost, time, and risk deltas straight from your evaluation ledger. And compliance isn’t waiting for annual PDFs anymore – they expect continuous monitoring.
- What’s not changing: The simple truth: great products still come from disciplined experimentation. The companies that learned this muscle memory in Web2 – measure, learn, ship – are about to lap everyone in AI. Because eval-led AI is just that same playbook, turned up to eleven.
2026 will be about adding confidence to every decision AI makes
The coming year is shaping up to be the year of AI evals. Not as an academic curiosity, not as a side-note in model papers, but as the backbone of how AI gets built, bought, and trusted. Budgets, contracts, and compliance are all shifting to an eval-first mindset.
The companies that master this shift will build safer, smarter systems, they’ll build faster, learn faster, and win faster.
The real question is: will you treat evals as a checkbox, or as the operating system of your AI strategy?